

Data changes over time, and businesses need to track these changes without losing important history. Customer addresses change, employee roles get updated, and product categories shift. Type 2 Slowly Changing Dimensions create a new record for each change while keeping all historical versions intact, allowing businesses to track the complete evolution of their data over time.

This approach differs from simply overwriting old data because it preserves every version of a record. When a customer moves to a new address, Type 2 SCD keeps both the old and new address records with date stamps and flags to show which version is current.
Understanding how to structure these tables and implement the right tracking methods can transform how organizations analyze trends and make decisions. The following guide covers everything from basic concepts to advanced implementation strategies that help data teams build robust historical tracking systems.
Key Takeaways
- Type 2 SCD maintains complete historical records by creating new rows for each data change instead of overwriting existing information
- Proper table structure requires surrogate keys, active flags, and start/end dates to track record versions effectively
- This method enables powerful time-based analysis but requires careful planning to manage storage costs and query performance
Defining Slowly Changing Dimensions and Their Role
Slowly changing dimensions (SCD) are database structures that capture how dimension data changes over time in a data warehouse. These dimensions work alongside fact tables to preserve historical records and enable accurate time-based analysis.
What Are Slowly Changing Dimensions?
Slowly changing dimensions are parts of a data warehouse that store information about business entities like customers, products, or employees. The term “slowly changing” means these attributes change infrequently rather than constantly.
Examples of SCD data include:
- Customer information: Address, phone number, job title
- Product details: Category, price tier, description
- Employee data: Department, manager, salary grade
SCD captures these changes without losing the original values. When a customer moves to a new address, the system keeps both the old and new addresses with date ranges showing when each was active.
Data changes in dimensions happen at irregular intervals. A customer might keep the same address for years, then suddenly move twice in one year. This unpredictable timing makes tracking changes important for accurate analytics.
Why Track Changes in Dimension Data?
Historical records in dimension data serve critical business and technical needs. Analytics engineers require accurate historical context to answer time-based questions and maintain data quality.
Business Requirements:
- Regulatory compliance for audits
- Customer behavior analysis over time
- Product performance tracking
- Sales territory changes impact
Technical Benefits:
- Data lineage preservation
- Machine learning feature accuracy
- Debugging data pipeline issues
- “As was” reporting capabilities
Without proper change tracking, businesses lose the ability to analyze how things looked at specific points in time. This creates gaps in understanding customer journeys, product evolution, and operational changes.
Difference Between Dimensions and Fact Tables
Dimensions and fact tables serve different purposes in a data warehouse structure. Understanding their roles helps explain why SCD focuses specifically on dimension data.
Dimension Tables:
- Store descriptive attributes about business entities
- Change infrequently but need historical tracking
- Contain textual and categorical data
- Examples: Customer names, product categories, store locations
Fact Tables:
- Record measurable business events and transactions
- Contain numeric values and foreign keys
- Update frequently with new records
- Examples: Sales amounts, order quantities, website clicks
Fact tables reference dimension data through foreign keys. When dimension data changes, fact tables need consistent ways to link to the correct historical version. This relationship makes SCD essential for maintaining data warehouse integrity and supporting accurate analytics across time periods.
Overview of Slowly Changing Dimension Types
Data warehouses use four main types of slowly changing dimensions to handle data changes. Each type offers different methods for tracking historical information and managing updates to dimension records.
Type 0 Dimensions and Use Cases
Type 0 dimensions represent data that never changes once it enters the data warehouse. These dimensions remain static throughout their lifecycle.
Common examples include birth dates, social security numbers, and original hire dates. The system blocks any attempts to modify these values after the initial load.
Key characteristics:
- No updates allowed after creation
- Original values stay permanent
- Simple to implement and maintain
Organizations use Type 0 dimensions when data accuracy requires preserving original values. Banks often apply this approach to account opening dates and customer identification numbers.
The main benefit is data integrity protection. Once loaded, the information cannot be accidentally changed or corrupted through updates.
Type 1 Dimensions Explained
Type 1 dimensions overwrite old values with new information when changes occur. This approach keeps only the current state of the data.
The system replaces existing attribute values directly in the same record. No historical tracking takes place with this method.
Process flow:
- System detects changed data
- Old value gets overwritten
- New value takes its place
- Historical information is lost
This approach works well for correcting data errors or when historical tracking is not needed. Customer address updates often use Type 1 processing.
Storage requirements stay minimal since only current values exist. However, analysts cannot perform historical trend analysis with this method.
Type 3 Dimensions and Limitations
Type 3 dimensions store both current and previous values in separate columns within the same record. This method provides limited historical tracking.
The dimension table includes columns like “Current_Address” and “Previous_Address” for each tracked attribute. Only the most recent change gets preserved.
Table structure example:
| Customer_ID | Current_Region | Previous_Region | Effective_Date |
|---|---|---|---|
| 123 | West | East | 2024-01-15 |
This approach allows simple before-and-after comparisons. Organizations can analyze the impact of recent changes on business metrics.
Major limitations include:
- Only one previous value stored
- Complex schema changes required
- Limited historical depth
Type 3 works best when tracking simple attribute changes with minimal history requirements.
Type 4 Dimensions Overview
Type 4 dimensions use separate tables to store current and historical data. This method combines the benefits of Types 1 and 2 approaches.
The current table holds only active records with the latest information. A separate history table maintains all previous versions of changed records.
Architecture components:
- Current table: Latest dimension values only
- History table: All previous versions with timestamps
- Linking mechanism: Connects current and historical records
This design optimizes query performance for current data while preserving full history. Most business reports use the current table for faster response times.
Historical analysis queries access the history table when needed. The separation reduces storage overhead in frequently accessed current tables.
Type 4 dimensions require more complex maintenance procedures. Database administrators must manage updates across both table structures simultaneously.
Type 2 Slowly Changing Dimensions Explained
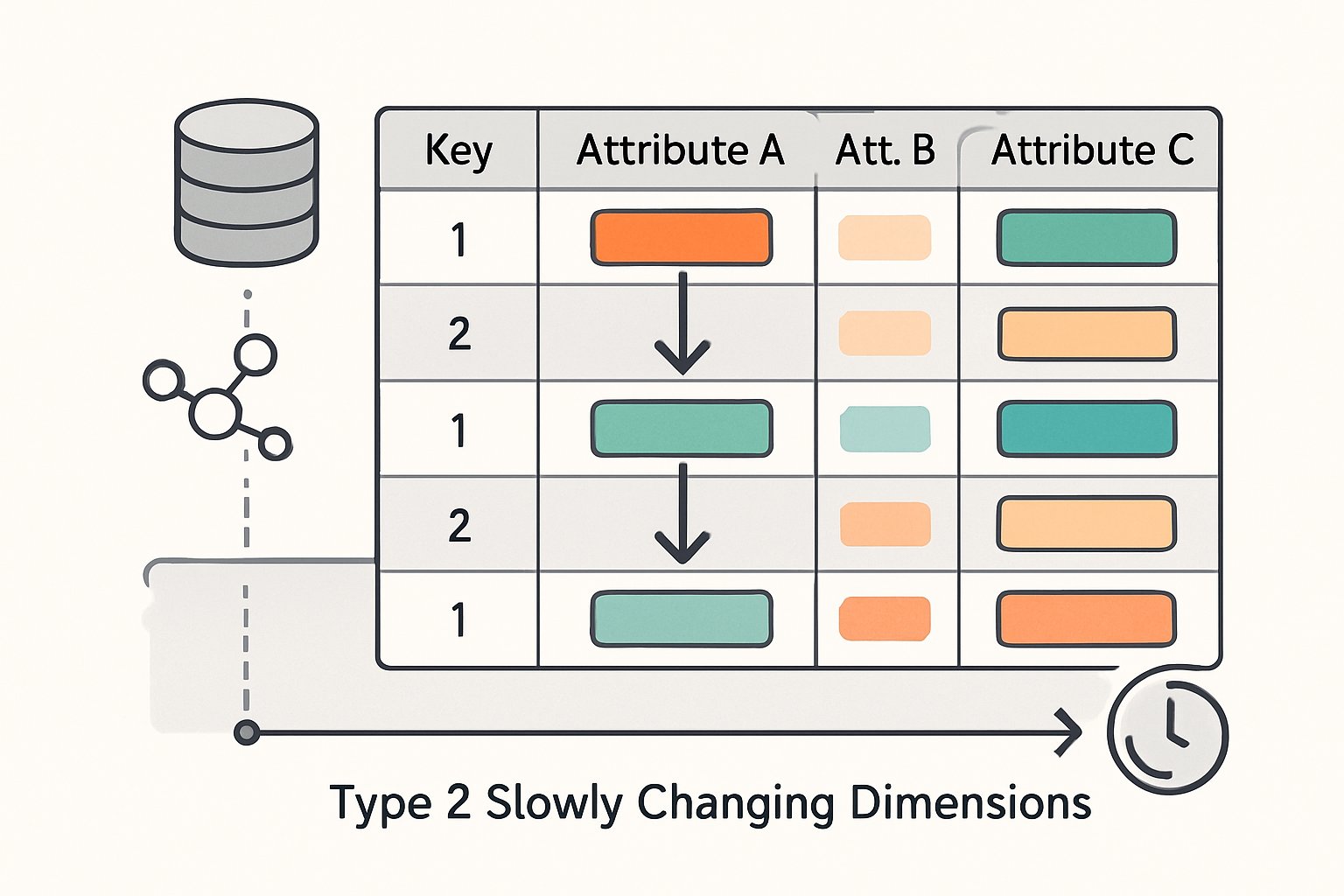
Type 2 SCD creates a complete audit trail by adding new records for each change while keeping old data intact. This method tracks when changes happen and maintains full historical context for business analysis.
Core Principles of SCD Type 2
Type 2 dimensions work by inserting new rows into dimension tables whenever attribute values change. The system never updates or deletes existing records.
Each record contains effective dates that show when the information was valid. A start date marks when the record became active. An end date shows when it was replaced.
Key components include:
- Unique business key (stays the same)
- Surrogate key (changes with each version)
- Effective start date
- Effective end date (null for current records)
- Version number or sequence
The current record has a null end date. This makes it easy to find the most recent version of any dimension member.
Change data capture (CDC) systems often feed Type 2 processes. They detect when source data changes and trigger the creation of new historical records.
How Type 2 Maintains Historical Data
When a change occurs, the system closes the current record by adding an end date. It then creates a new record with the updated information and a new start date.
The old record stays in the dimension table permanently. This creates a complete timeline of all changes for each business entity.
Example of customer address change:
| Customer_Key | Customer_ID | Name | Address | Start_Date | End_Date |
|---|---|---|---|---|---|
| 1001 | CUST_001 | John Smith | 123 Oak St | 2024-01-01 | 2024-06-15 |
| 1002 | CUST_001 | John Smith | 456 Pine Ave | 2024-06-16 | NULL |
Historical tracking works by joining fact tables to dimension tables using both the surrogate key and date ranges. This ensures reports show the correct attribute values for any point in time.
Type 2 dimensions support time-based analysis without complex queries. Users can easily see what information was current during specific periods.
Use Cases for Type 2 Implementation
Customer management benefits greatly from Type 2 dimensions. Companies track address changes, phone number updates, and status modifications over time.
Product catalogs use historical records to show price changes, category moves, and specification updates. This helps analyze pricing strategies and product evolution.
Employee data requires careful historical tracking for compliance. Type 2 dimensions capture salary changes, department transfers, and role promotions with exact dates.
Regulatory compliance often demands complete audit trails. Financial institutions use Type 2 dimensions to meet requirements for data retention and change tracking.
Market research relies on historical data to identify trends. Type 2 dimensions let analysts compare customer behavior across different time periods using accurate historical context.
Sales analysis becomes more accurate when territory changes and sales rep assignments are tracked historically. This prevents distorted performance metrics caused by organizational changes.
Structuring Type 2 SCD Tables
Type 2 SCD tables require specific structural elements to track data changes over time. The key components include surrogate keys for unique identification and timestamp columns to mark when records become active or inactive.
Surrogate Keys vs Natural Keys
A surrogate key serves as the primary key in Type 2 SCD tables. This is different from the natural key that comes from the source system.
The surrogate key is an artificial identifier. It gets created specifically for the data warehouse. Each new record receives a unique surrogate key value.
The natural key is the original identifier from the source system. When a customer’s address changes, the natural key stays the same. However, the system creates a new record with a new surrogate key.
This design allows multiple records for the same entity. Each record represents a different time period. The natural key links all versions together while the surrogate key makes each record unique.
Designing Timestamp and Flag Columns
Timestamp columns track when each record becomes active and inactive. Most implementations use two columns: start date and end date.
The start date shows when the record became current. The end date shows when it was replaced. Active records have a null end date or a future date like 9999-12-31.
Some tables include a flag column to mark current records. This makes queries faster since checking a flag is quicker than comparing dates.
The timestamp column design affects query performance. Proper indexing on these columns helps the database find current and historical records quickly.
Implementing and Maintaining SCD Type 2
Successful SCD Type 2 implementation requires robust change detection methods, automated tooling, and strong data quality controls. Data engineers must establish reliable processes to capture changes, load data efficiently, and maintain accuracy across all historical records.
Change Detection and Data Loading Strategies
Change Data Capture (CDC) provides the most efficient method for detecting changes in source systems. CDC tracks modifications at the database level and captures only changed records.
This approach reduces processing time compared to full table scans. It also minimizes the risk of missing updates during data extraction.
Full table comparison serves as an alternative when CDC is not available. This method compares current source data against the existing dimension table to identify changes.
Data engineers typically implement incremental loading strategies to handle new and updated records. The process involves:
- Identifying changed records through timestamps or hash comparisons
- Creating new rows for modified attributes
- Updating effective and expiry dates
- Setting active flags appropriately
Batch processing works well for most SCD Type 2 implementations. However, real-time processing may be necessary for systems requiring immediate historical tracking.
Tools and Automation (Including Fivetran)
dbt offers built-in SCD Type 2 functionality through snapshots and specialized macros. These tools automate the creation of new records and management of effective dates.
Fivetran simplifies SCD Type 2 implementation by automatically detecting schema changes and maintaining historical records. It handles the technical complexity while ensuring data consistency.
Delta Live Tables in Databricks provides the APPLY CHANGES INTO syntax. This feature streamlines synchronization and maintains dimension table integrity automatically.
Popular automation tools include:
- SSIS for Microsoft environments
- Matillion for cloud data warehouses
- Airbyte for open-source solutions
- Custom Python scripts for specific requirements
These tools reduce manual effort and minimize errors in SCD Type 2 processes. They also provide monitoring capabilities to track data loading success and failures.
Ensuring Data Quality in SCD Type 2
Data validation rules must verify that only one active record exists per business key at any time. This prevents duplicate active records that could cause reporting errors.
Effective date validation ensures that date ranges do not overlap or contain gaps. Each record’s effective date should match the previous record’s expiry date.
Key data quality checks include:
- Surrogate key uniqueness across all records
- Business key consistency within the same entity
- Date range continuity without overlaps or gaps
- Active flag accuracy with only one active record per entity
Automated testing should run after each data load to catch quality issues early. Data engineers can implement these tests using tools like dbt or custom validation scripts.
Data lineage tracking helps identify the source of quality problems when they occur. This visibility enables faster troubleshooting and resolution of data issues.
Business Value and Analytical Benefits
SCD Type 2 delivers measurable business value by preserving complete data history and enabling accurate trend analysis. Organizations gain the ability to track changes over time while meeting regulatory requirements and supporting complex analytical workflows.
Enabling Historical Analysis
SCD Type 2 creates a complete timeline of data changes that supports advanced historical analysis. Businesses can examine how customer preferences, product attributes, or market conditions evolved across specific time periods.
Financial institutions use this capability to track credit score changes over time. They can analyze lending decisions made at different points in a customer’s credit history.
Retail companies examine customer segment migrations. They identify when customers moved from one demographic group to another and measure the impact on purchasing behavior.
Healthcare organizations track patient information changes. They can review treatment outcomes based on historical patient data rather than current information only.
The temporal lineage created by SCD Type 2 allows analysts to produce trustworthy analytics. They can recreate reports exactly as they appeared on any historical date.
Meeting Business Requirements
Many industries face strict regulatory requirements for data retention and audit trails. SCD Type 2 automatically creates the necessary historical records to satisfy these compliance needs.
Banks must demonstrate how customer risk profiles changed over time for regulatory audits. The complete history preserved in SCD Type 2 tables provides this documentation.
Insurance companies need to show how policy terms evolved. They can prove what coverage was active on specific claim dates using historical dimension data.
Tax reporting requires businesses to use data values that were current during each reporting period. SCD Type 2 ensures accurate historical tax calculations.
Data integrity improves because no historical information gets lost or overwritten. Organizations maintain a permanent record of all changes with timestamps and version tracking.
Supporting Data Analysts and Engineers
Data analysts benefit from simplified historical reporting workflows. They can query any point in time without complex data reconstruction processes.
Analysts create trend reports by filtering records based on effective date ranges. They compare current values against historical baselines using straightforward SQL queries.
Engineers implement SCD Type 2 patterns that automatically handle change detection and record versioning. This reduces manual coding effort for historical data management.
Data pipelines become more reliable because historical context never gets lost during updates. Engineers can troubleshoot data issues by examining the complete change history.
Performance improves for time-based queries since historical records remain readily accessible. Analysts avoid expensive data restoration processes from backup systems.
Challenges and Best Practices for SCD Type 2
SCD Type 2 implementation requires careful planning to avoid data integrity issues and performance problems. Key challenges include managing unique keys properly and handling schema changes in dimension tables.
Common Pitfalls to Avoid
Setting incorrect unique keys causes the most serious problems in SCD Type 2 implementations. The unique key must stay the same over time and identify each business entity clearly. Many teams pick keys that change or include multiple null values.
Missing updated_at timestamps breaks the change detection logic completely. Without reliable timestamps, the system cannot tell when records changed. This leads to missed updates or duplicate historical records.
Overwriting history accidentally happens during full refresh operations. Teams often run full refreshes without understanding they will lose all historical data in their dimension tables.
Poor performance planning creates slow queries as tables grow larger. Wide dimension tables with many columns take longer to process. Teams also forget to add proper indexing on date ranges and unique keys.
Schema changes without proper handling cause snapshot failures. When source tables add or remove columns, existing snapshots may break unless configured to handle schema evolution properly.
Recommended Approaches for Longevity
Use surrogate keys for change tracking instead of relying only on business keys. Generate hash values from all tracked columns to detect any field changes. This approach catches updates even when teams add new columns later.
Implement proper partitioning strategies to maintain good performance. Partition dimension tables by effective date ranges. This keeps query performance fast as historical data grows over years.
Set up automated testing and validation to catch data quality issues early. Test that each unique key has only one active record. Validate that effective date ranges do not overlap for the same entity.
Plan for schema evolution by configuring snapshots to handle new columns. Use settings that append new columns instead of failing when source schemas change.
Monitor data warehouse storage costs by setting retention policies for very old historical records. Archive records older than regulatory requirements to separate storage systems.
Frequently Asked Questions
Type 2 Slowly Changing Dimensions create multiple records for each entity when changes occur. This approach preserves complete historical data but requires specific implementation strategies and performance considerations.
What are the main differences between Type 1 and Type 2 Slowly Changing Dimensions?
Type 1 simply overwrites existing dimension records when changes occur. This method loses all historical information permanently.
Type 2 creates a new record for every change. The original record stays in the table unchanged.
Type 1 maintains only current data. Type 2 keeps every version of the data over time.
Type 2 uses surrogate keys to identify each record version. Type 1 typically uses natural business keys.
Date ranges or current flags help identify which Type 2 record is active. Type 1 records are always current by default.
Can you provide an example of how to implement a Type 2 Slowly Changing Dimension?
A customer dimension table needs columns for surrogate key, business key, attributes, and control fields. The surrogate key uniquely identifies each record version.
Control fields include effective date, end date, and current flag. These track when each record version was active.
When a customer address changes, the system updates the old record’s end date and current flag. It then inserts a new record with the updated address.
The old record gets an end date of yesterday and current flag set to ‘N’. The new record gets today’s effective date and current flag set to ‘Y’.
Hash values can detect changes by comparing attribute combinations. This makes change detection faster than comparing each field individually.
How do Type 2 Slowly Changing Dimensions handle historical data tracking?
Type 2 dimensions preserve every attribute change as separate records. Each record represents the entity’s state during a specific time period.
Effective and end dates define when each record version was valid. Current records typically use a future date like ‘9999-12-31’ for the end date.
Fact tables join to dimensions using both business keys and date ranges. This ensures facts connect to the correct dimension version for their time period.
Historical analysis becomes possible by querying specific date ranges. Users can see exactly what data looked like at any point in time.
The complete audit trail supports regulatory compliance requirements. Organizations can prove what information existed when decisions were made.
What are some common best practices for managing Type 2 Slowly Changing Dimensions?
Surrogate keys should be used in fact table relationships instead of business keys. This approach prevents issues when business keys change or become null.
Default end dates should use distant future values like ‘9999-12-31’. This simplifies join conditions using BETWEEN operators.
Hash columns help detect changes efficiently across multiple attributes. Computing hashes is faster than comparing each field individually.
ETL processes should be idempotent so reruns produce identical results. Transaction boundaries and MERGE statements help achieve this consistency.
Indexes on business keys and current flags improve query performance. Partitioning by current flag or effective year can also help large tables.
In what scenarios should a Type 2 Slowly Changing Dimension be favored over Type 3?
Type 2 works better when unlimited historical versions are needed. Type 3 only tracks current and previous values.
Regulatory compliance often requires complete audit trails. Type 2 preserves every change while Type 3 loses older history.
Time-travel analytics need access to all historical states. Type 2 supports any point-in-time analysis requirements.
Machine learning features may need historical attribute values. Type 2 provides the complete dataset for model training.
Debugging data issues requires seeing past dimension states. Type 2 enables replaying historical pipeline runs accurately.
Are there any potential performance impacts to consider when using Type 2 Slowly Changing Dimensions?
Dimension tables grow larger because they store multiple records per entity. Storage costs increase compared to Type 1 approaches.
Join operations become more complex with date range conditions. Queries must filter on both business keys and effective dates.
Index maintenance overhead increases with more records and columns. Additional indexes on date and flag columns are often necessary.
ETL processing takes longer due to change detection logic. Hash calculations and record comparisons add processing time.
Query performance may suffer without proper indexing strategies. Partitioning and archiving old records can help manage large tables.



