
Become an analytics engineer worth hiring.
Master SQL, dbt, BigQuery, Python, and AI-assisted analytics workflows through graded exercises, real projects, and a portfolio-ready capstone — built around the work analytics engineers ship every day.
Return a unique list of cities from the customers table. Alias the column as `unique_city`.
SELECT DISTINCT city AS unique_city
FROM customers;| unique_city |
|---|
| San Francisco |
| Los Angeles |
| Brooklyn |
| Austin |
| Chicago |
Theory doesn't get you hired.
Most data courses teach you what a window function is. Almost none teach you what to do when one returns the wrong row count in a production dbt model at 2:30 PM on a Friday.
This platform was built by analytics engineers who've been on that call. The exercises are the queries we've actually written. The projects are the kinds of problems that show up in real interviews. The capstone is the work you'll be doing on day one of the job.
Hi, I'm Eric.
I've spent the last decade as an analytics engineer at Disney, Hulu, Nike, Peloton, and Gopuff — designing the data layer that hundreds of analysts, scientists, and PMs depend on every day.
For the past five years I've also mentored people transitioning into data engineering. The pattern I saw over and over: people would finish a $1,000 bootcamp and still not be able to ship a dbt model, write a window function, or explain what a fact table is in an interview.
This platform is the curriculum I wish I'd had — built around the actual work analytics engineers do, not the theory of it.
~2 min watch
People trust Eric to teach them this.
- ★★★★★
“Such a great mentor, and so calm and understanding. As a newbie to SQL I found it intimidating, but I appreciate Eric's support throughout. 10/10 would recommend.”
Verified Codementor menteeLearning SQL from scratch - ★★★★★
“With only 2 sessions I'm confident I can improve my SQL, Python, and Snowflake skills. Go with Eric — you can't go wrong.”
Verified Codementor menteeSQL · Python · Snowflake - ★★★★★
“Walked in terrified of SQL and now I feel ready to learn more. Eric was candid about his experience and shared resources and tips that can help my career.”
Verified Codementor menteeSQL · career advice
Ten modules. End-to-end.
Built around the work analytics engineers ship every day — no filler, no theory-for-theory's sake.
- 01
Welcome to Analytics Engineering
What an analytics engineer actually does, how the role fits into a modern data team, and the workflow you'll repeat for every project.
- Role & responsibilities
- Data team org structure
- End-to-end workflow
- 02
Data Fundamentals
The conceptual foundation: types and structures, warehouse architecture, ETL vs ELT, and how data moves through a modern stack.
- Data warehouses
- ETL / ELT
- API fundamentals
- 03
SQL for Analytics Engineers
From SELECT to window functions, CTEs, and query optimization — every SQL pattern an analytics engineer needs in production.
- Joins & subqueries
- Window functions & CTEs
- Performance tuning
- 04
Data Modeling & Architecture
Star and snowflake schemas, normalization tradeoffs, slowly changing dimensions, and how to design models that scale.
- Dimensional modeling
- Normalization
- SCDs
- 05
dbt and GitHub
dbt models, tests, snapshots, and macros — combined with the GitHub workflow analytics teams use to ship to production.
- dbt projects
- Tests & snapshots
- PR workflow
- 06
Data Quality & Testing
Unit, integration, and acceptance testing for data. dbt testing patterns. Observability and alerting on production pipelines.
- Test types
- dbt tests
- Observability
- 07
Programming for Analytics Engineers
Python where it matters: pandas, NumPy, automation scripts, CI/CD, and integrating Python into your data stack.
- pandas & NumPy
- Automation
- CI/CD
- 08
Visualization & Reporting
Looker, Tableau, and Power BI — dashboard design principles and the patterns that make stakeholders actually use your reports.
- Dashboard design
- Looker
- Stakeholder reporting
- 09
AI Tools Mastery
ChatGPT, Claude, and Cursor for the analytics engineering workflow. Prompt patterns for SQL review, dbt generation, and modeling.
- ChatGPT for SQL
- Cursor agents
- Prompt patterns
- 10
Capstone Project
Build a complete dbt project on BigQuery: source → staging → intermediate → mart, then publish a Looker dashboard. Portfolio-ready.
- BigQuery + dbt Cloud
- Full pipeline
- Portfolio writeup
1,598 graded exercises.
Every exercise has a schema, a question, a hint, and a worked solution with an explanation. SQL, Python, dbt, data modeling, and ETL/ELT — across 48 topics. A curated sample of the SQL fundamentals is free without an account.
From the orders table, show each customer_id and their total order count. Order by count descending.
SELECT customer_id, COUNT(*) AS order_count\nFROM orders\nGROUP BY customer_id\nORDER BY order_count DESC;| unique_city |
|---|
| San Francisco |
| Los Angeles |
| Brooklyn |
| Austin |
| Chicago |
See what students ship.
A real GitHub repo, a deployed dbt project on BigQuery with scheduled jobs in dbt Cloud, and a two-page Looker Studio dashboard you can walk a stakeholder through.
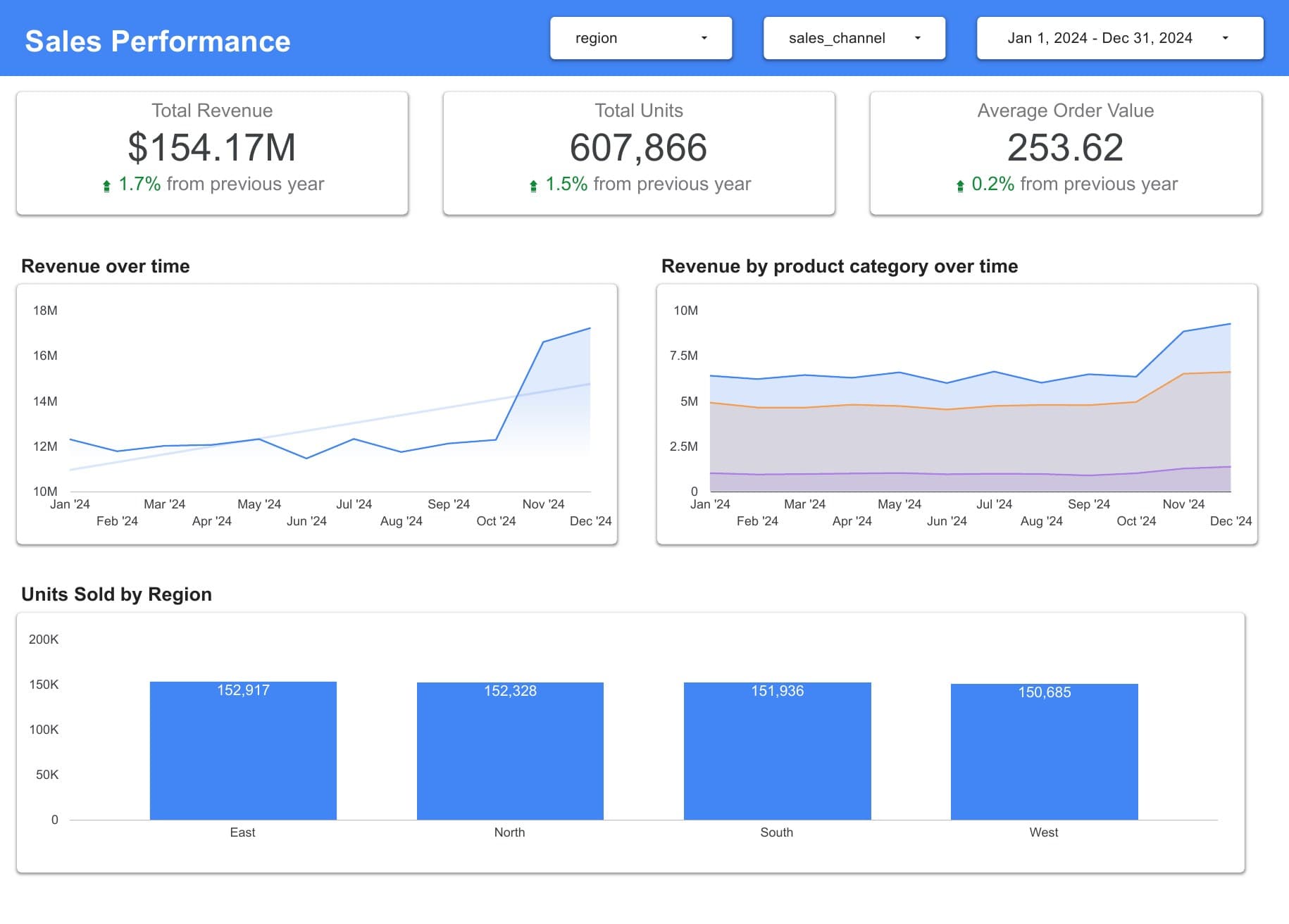
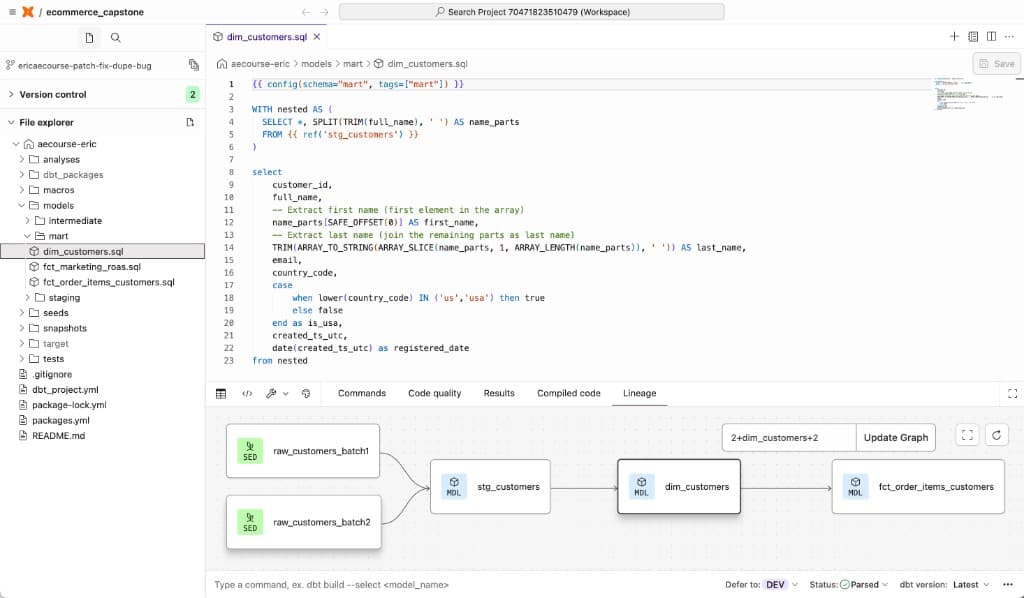
Read the playbook.
Long-form articles covering the analytics engineering toolkit, written by working engineers. 84 pieces, free.
- Interviews
Analytics Engineering Interview Mistakes and How to Avoid Them: A Complete Guide
Discover common analytics engineering interview mistakes and learn strategies to avoid them. Enhance your preparation and communication skills for success.
- AI
How Generative AI is Changing the Role of Analytics Engineers: New Skills, Workflows, and Impact
Generative AI transforms analytics engineering by automating tasks, shifting focus from coding to strategic oversight, and requiring new AI-related skills.
- Fundamentals
Automated Data Catalogs: DataHub vs Amundsen vs Atlan Compared
Compare DataHub, Amundsen, and Atlan for automated data cataloging. Understand their governance, setup, and enterprise capabilities to choose the best fit.
- dbt
dbt Macros & Jinja Tips Every Analytics Engineer Should Know: Expert Guide
Learn how dbt macros and Jinja can transform repetitive SQL tasks into dynamic, reusable code, enhancing scalability and efficiency in data projects.
- dbt
dbt Cloud vs Core: Feature Comparison 2025—Comprehensive Guide
Compare dbt Cloud and Core to understand their features, costs, and operational differences. This guide helps data teams make informed decisions.
- Architecture
Apache Airflow vs Prefect: Which Scheduler for Analytics Engineering?
Explore the differences between Apache Airflow and Prefect, focusing on workflow design, ease of use, and integration to choose the right scheduler for your team.
One payment. Lifetime access.
The full curriculum, every exercise, the capstone, the GPT tutor, and every future update. 30-day refund if it isn't for you.
If you're wondering, you're not alone.
I have zero technical background. Is this really for me?
Yes. The curriculum starts from the fundamentals — what a relational database is, what a SELECT statement does, what an analytics engineer's day looks like. Your pace is up to you; the platform tracks your progress and lets you leave and return without losing place.
How is this different from a free YouTube playlist or a $50 Udemy course?
Free tutorials cover isolated concepts. This is a complete curriculum with graded exercises, a portfolio capstone, and a coherent path from beginner to job-ready. The 1,598 exercises aren't passive — they're checked. The capstone is a real BigQuery + dbt Cloud build you can put on GitHub.
How long will it take?
Depends on how much time you can give it. 10–15 hours a week typically takes about three months. Moonlighting around a full-time job, expect six. The platform tracks your progress so you can pause and resume without losing place.
What if I get stuck?
Every lesson and exercise has a built-in GPT tutor — it knows the context of what you're looking at and can explain, hint, or walk through the problem with you.
Is my work graded? Is there an instructor?
The course is self-paced. Exercises and project steps auto-grade instantly in your browser — write a query, run it, and it's checked against the expected result, with the GPT tutor on hand when you're stuck. The one deliverable a human reviews is the capstone: you submit your GitHub repo and dashboard and get a status plus written feedback. For line-by-line review of your code, portfolio, and interview prep, 1-on-1 coaching is available separately.
Is the content kept up to date?
Yes. The dbt and analytics-engineering ecosystems move quickly; the curriculum is updated to reflect current versions and patterns. Lifetime access means you get every update.
What if it's not for me?
30-day refund. Try the first three modules, do the exercises, and if it's not delivering value, email and you'll get a full refund.
Will the AI tools section help me in interviews?
Yes. Hiring managers increasingly screen for AI fluency. Module 9 covers ChatGPT prompt patterns for SQL review, dbt generation, modeling, and how to use Cursor as a coding partner — concrete skills you can demonstrate in a screen.
Ship analytics like an engineer.
Free training is on the house. No credit card, no upsell, no countdown timer.